By Richard Lander, CTO | May 3, 2024
The Kubernetes control plane is a distributed software system that provides the container orchestration features of Kubernetes. If you'd like a higher level overview of Kubernetes in general, see our blog post: What is Kubernetes?.
By the end of this blog post, you'll have a general understanding of how the Kubernetes control plane works and what its most important components are. I'll give examples of what happens in the control plane when a user creates a Kubernetes deployment resource to give you a clear look at what goes on under the Kubernetes hood. I've left out some considerable detail in the name of making this an approachable topic. Kubernetes is a complex, feature-rich system that has many moving parts. The primary objective here is to give you a clear idea of the patterns of implementation in the Kubernetes control plane that you can apply to other parts of the system.
Persistence Layer
The database for Kubernetes is etcd. It is a distributed key-value store. It does not require a pre-defined data schema the way a SQL database does. One of the features of etcd is that it supports clients watching for changes to data so they can respond to those changes.
Note: It is possible to run Kubernetes on an alternative DB to etcd using the kine project which is a shim that the Kubernetes API connects to.
Kubernetes API
The Kubernetes API is a RESTful API with the implementation of an important additional verb: WATCH. The WATCH verb exposes etcd's watch mechanism to allow API clients to get notifications of changes to resources they care about.
All operations in the Kubernetes control plane are coordinated through the API. No other part of the control plane connects to etcd to read or write data besides the API.
When a Kubernetes user creates a deployment with the kubectl CLI tool, kubectl connects to the API to make the change. The API performs necessary authN, authZ and resource schema validation, then persists the resource in etcd.

Once the resource has been persisted, the watch mechanism comes into play. Let's explore that next in the next section on controllers.
Controllers
When they start, Kubernetes controllers initiate a watch on the resource kinds they have responsibility for. When a resource is created, updated or deleted, the controller is notified via a response on the watch connection so they can take action to reconcile the state the user has requested.

Controller Manager
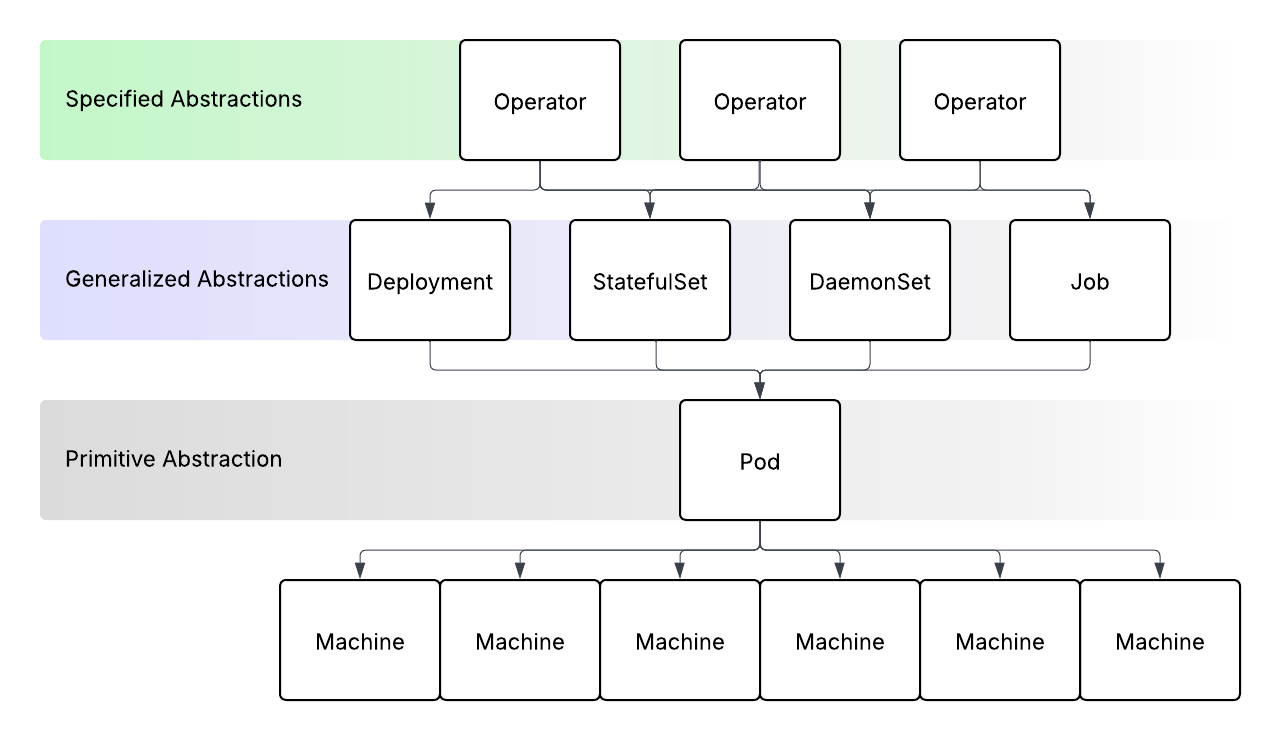
When a user creates a deployment resource, the deployment controller is notified. The deployment controller is one of a number of controllers that live within the kube-controller-manager in a Kubernetes control plane. Its job is to create a replicaset resource in response to the creation of a deployment resource.
The repliaset controller is notified of the creation of a repliaset resource and responds by creating the pods. It creates as many pods as are defined in the spec.replicas field of the repliaset - which was originally defined in the same field of the deployment.

Note: At this point, you may wonder: Why do we need a replicaset? Why can't the deployment controller create the pod resources? The answer is not evident at create-time, but rather when updates to the deployment occur. The deployment controller is responsible for managing the update strategy and it manages repliasets in doing so.
Scheduler
The scheduler is notified when pod resources are created. The scheduler's job is to find the best machine in the cluster to run each pod on. In Kubernetes, machines are represented by node resources. Scheduling pods is pretty simple in concept, however doing it well is quite complex in reality. The scheduler uses an involved set of rules to determine which node a pod should be deployed to. Once it has determined which node a pod will be assigned to, it updates the spec.nodeName field on each pod resource.

Fun fact: you can bypass using the scheduler to assign a pod to a node by manually setting the value of the spec.nodeName field yourself.
Kubelet
A kubelet runs on every node in the cluster. When a pod is assigned to a node, the kubelet for that node is responsible for getting the container/s for a pod up and running. It pulls the container image for each container in the pod and instructs the container runtime - usually containerd - to start the containers.

That completes the process of operations that occurs to bring the workload's containers up when a user creates a deployment resource.
Patterns of Implementation
There are some important takeaways from this. You'll notice none of the controllers communicate directly with one another. Each controller connects to the API server and responds to changes in the system by carrying out its function when needed. This makes the system very composable and extensible. For example, if you had special requirements for scheduling pods in your cluster, you could switch out the default scheduler with one of your own design, using rules you define for assigning pods to nodes.
All controllers use non-terminating loops to reconcile state if an unmet condition is encountered the prevents it from completing its task. For example, if the kubelet fails to pull the image needed to run the container, it will retry that operation until it succeeds. That way, if there's a temporary network interruption with the image registry, when the connection is restored, it will succeed. Also, if the scheduler fails to schedule a pod because there's is insufficient available compute on any of the nodes to accommodate the new pod, it will retry until it succeeds (or the pod is deleted). If a new node is added to the cluster, it will succeed on its next retry and the desired condition of the cluster will be reached. This gives a peek into the extensibility of Kubernetes. Adding a cluster autoscaler that adds nodes to the cluster when pods cannot be scheduled for lack of compute resources will provide extended capabilities. Human intervention will not be required to ensure pods will always have enough nodes to run and that cluster capacity will be managed according to the workload's needs.
Extensibility
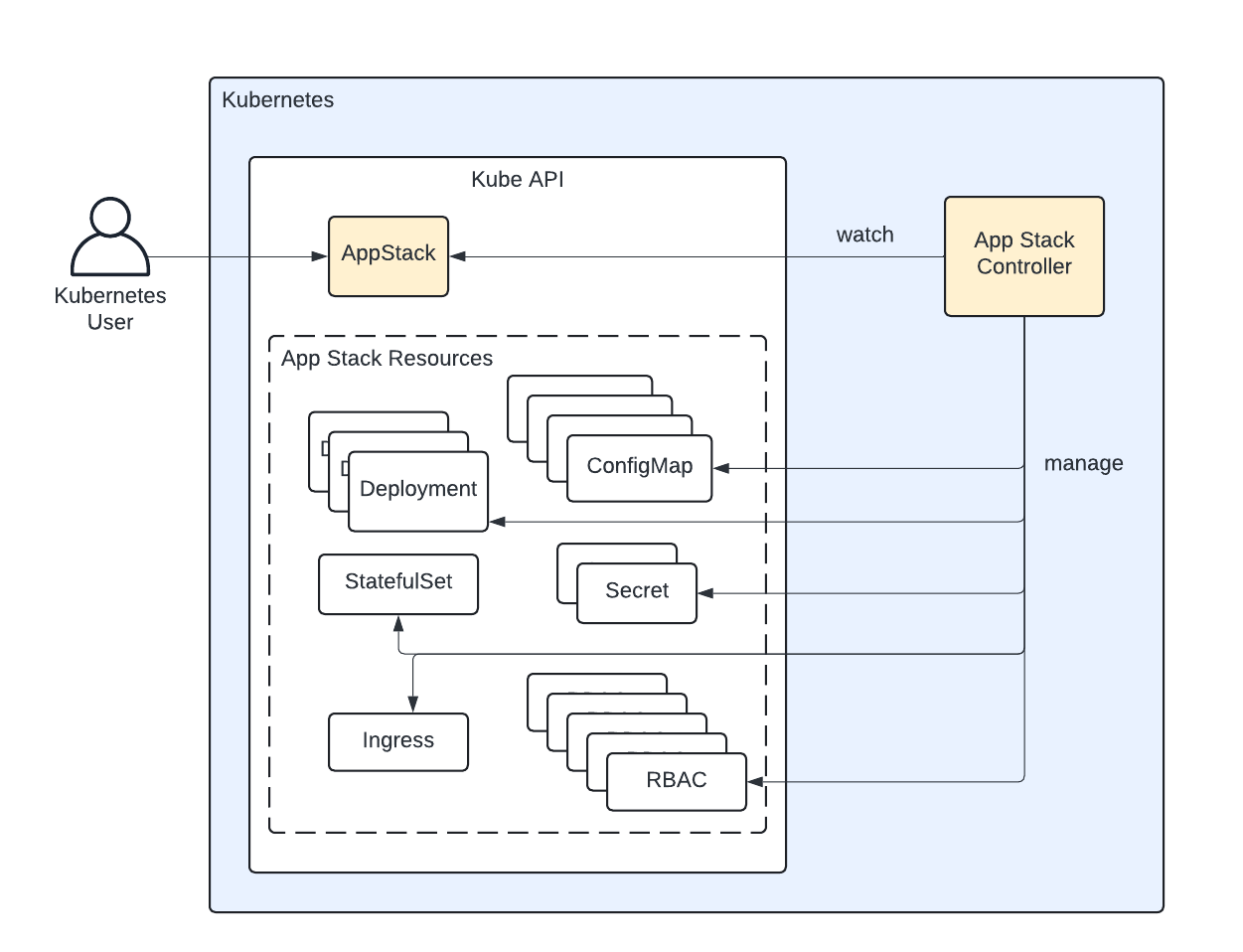
Kubernetes is a very effective system for orchestrating containers. However, arguably its greatest feature is its extensibility. You can create custom objects and build your own custom controllers and plug them into any Kubernetes control plane to add new features. This is known as the operator pattern and is underused today by platform engineers. This can greatly reduce complexity in software delivery systems that deploy workloads to Kubernetes by providing custom abstractions for high-value workloads. This is one of the keys to providing true self-service platforms to developers.
If you'd like to learn more about Kubernetes operators, see our blog post: What is a Kubernetes Operator?
Threeport
Threeport is a cloud native application orchestrator that manages Kubernetes clusters and the apps that run there. Its architecture is based in part on that of Kubernetes. However, it does not orchestrate containers - Kubernetes does a great job of that. Instead, Threeport orchestrates applications by managing cloud infrastructure, and the Kubernetes clusters used to run the applications. It also manages the support services that need to be installed on Kubernetes, as well as the provisioning of managed services, connecting them to your app at runtime. If you're interested in running workloads on Kubernetes, download the Threeport CLI from GitHub and check out the documentation.
Qleet
Qleet is a managed Threeport provider. Similar to Kubernetes, it is not difficult to stand up a Threeport control plane and try it out for testing purposes. However, managing a complex control plane in production can be risky without knowing the details of how that control plane works. So Qleet offers managed Threeport control planes, supported by the creators of the Threeport project.