By Richard Lander, CTO | Nov 6, 2023
Qleet is building Threeport, an application orchestrator developed from scratch and from first principles. It exists to eliminate toil in the deployment and ongoing management of software systems.
As of this writing, you can download and try out Threeport, however the source code is not yet publicly available. We're planning to open-source it soon. We're making it available for people to try it out and provide feedback. It's not yet production-ready and is missing some key features - but the foundation is ready for you to evaluate and we're keen to hear what you think.
Before we delve into Threeport, let's examine some of the challenges that exist today in managing "cloud native" applications.
Challenges
Kubernetes
Kubernetes has emerged as the industry standard for orchestrating containerized workloads. Nevertheless, its complexity can be a stumbling block for many development teams, especially smaller ones. Those that can't afford a fully supported solution or lack the engineering capacity to manage it often resort to more user-friendly solutions like Docker Compose or GCP Cloud Run. These solutions are great for quick and simple setups but can impose limitations and restrict flexibility as your software evolves. Furthermore, in the case of cloud provider services, you can end up locked into a vendor's product. In any case, even large enterprises find it challenging to construct application platforms on Kubernetes that are truly developer-friendly.
What if we had an open-source solution that makes Kubernetes as easy to use as Cloud Run, while also providing the flexibility to leverage Kubernetes' capabilities whenever needed?
Software Delivery
Here at Qleet, we diverge from the current orthodoxy on this topic. GitOps is a poor solution to software delivery for most modern production systems. It is useful in less complex cases, and is a natural development for managing cloud native software deployment configs. However, as systems grow in sophistication, GitOps becomes an anti-pattern for two reasons:
-
It uses git repositories as the data store for system configuration. Git is an excellent tool for managing the source code for software. Not so much for system configuration. The reason can be illustrated by the fact that modern GitOps systems generally take a bunch of templated configs, run them through a rendering process and write them to a "real" database, etcd in the case of Kubernetes. Effectively, your "source of truth" in git is being copied to a database. Your source of truth, and the variables that are currently managed with templates, should be in a database.
The primary difference between a database and a git repository is that a database is designed for software to read and write content. We need to begin using software to manage the complexity of deployment configs. When the end user of a web application wants to update a database, they don't write a SQL statement, they interface with an app that abstracts the details and usually executes a collection of statements in a transaction. Similarly, a developer or platform engineer should not be modifying templates and overlays in their IDE. They should be providing an abstracted desired state to an application that can manage the changing values across all the systems it affects.
-
GitOps delivery systems are a chain of disparate tools, each with their unique config syntax and expertise requirements. And even with the requisite expertise, you soon find yourself managing ArgoCD configs that run Helm charts as well as Kustomize overlays. You, the human being, wind up juggling overlapping concerns between different tools and configs. This labyrinth of configuration leaves most wishing for a decoder ring when trying to troubleshoot a problem. Add in the interplay between infrastructure configuration and the workloads that run on the infra, and you often find yourself contriving bespoke mechanisms to plumb values between Terraform configs and Kubernetes manifest templates. Maneuvering these concerns feels like trying to change your pants while driving a car with your forehead glued to the steering wheel. Developers just want to ship code.
What's missing is a set of composable software controllers that manage the source of truth for your system configuration in a database. This approach allows us to develop systems that plumb values properly based on high-level input. GitOps pipelines commonly manage a mountain of configuration, often thousands of lines of templated and overlaid YAML. Developers and platform engineers are too often fiddling with label selectors on Service resources and annotations on Ingress resources when they just want to expose their app securely to the public internet.
That brings us back to our core topic: What is Application Orchestration?
Application Orchestration
What it Is
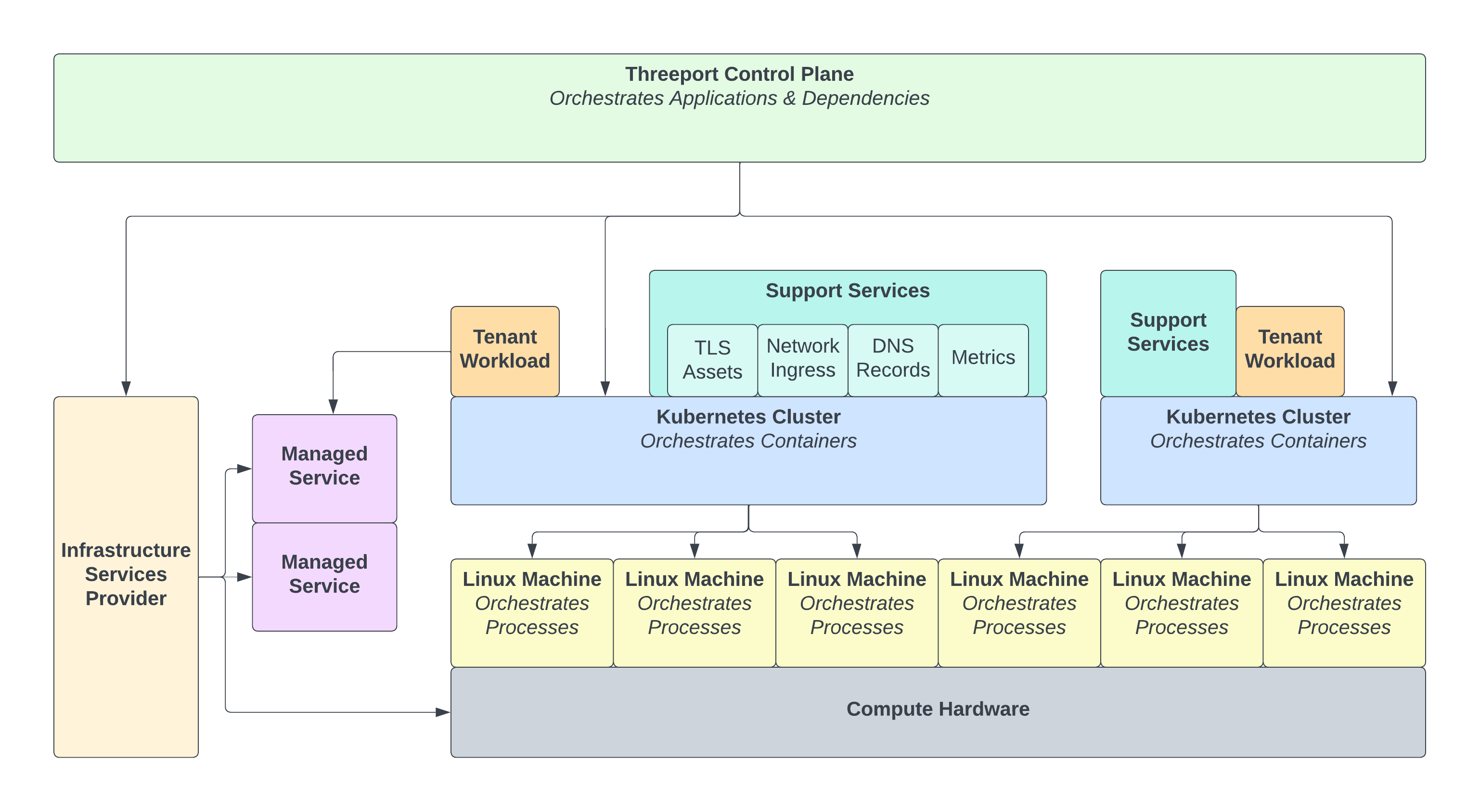
Applications are much more than just source code, compiled artifacts and container images. They have many external dependencies:
- Infrastructure: Applications need computers and network connections to function, and this infrastructure must be tailored for the applications running on it.
- Container Orchestration: In a Kubernetes world, an app first needs a properly deployed cluster. It then needs its configurations - Kubernetes manifests - to define the resources that allow a container to properly run and serve the end user.
- Support Services: An application inevitably needs support services, such as an ingress layer to properly route incoming requests, certificates to terminate TLS connections, DNS records to provide IP addresses for clients, log aggregation, metrics collection, etc.
- Managed Services: Often, applications leverage managed services offered by cloud providers. Managed databases and object stores are just a couple of obvious examples.
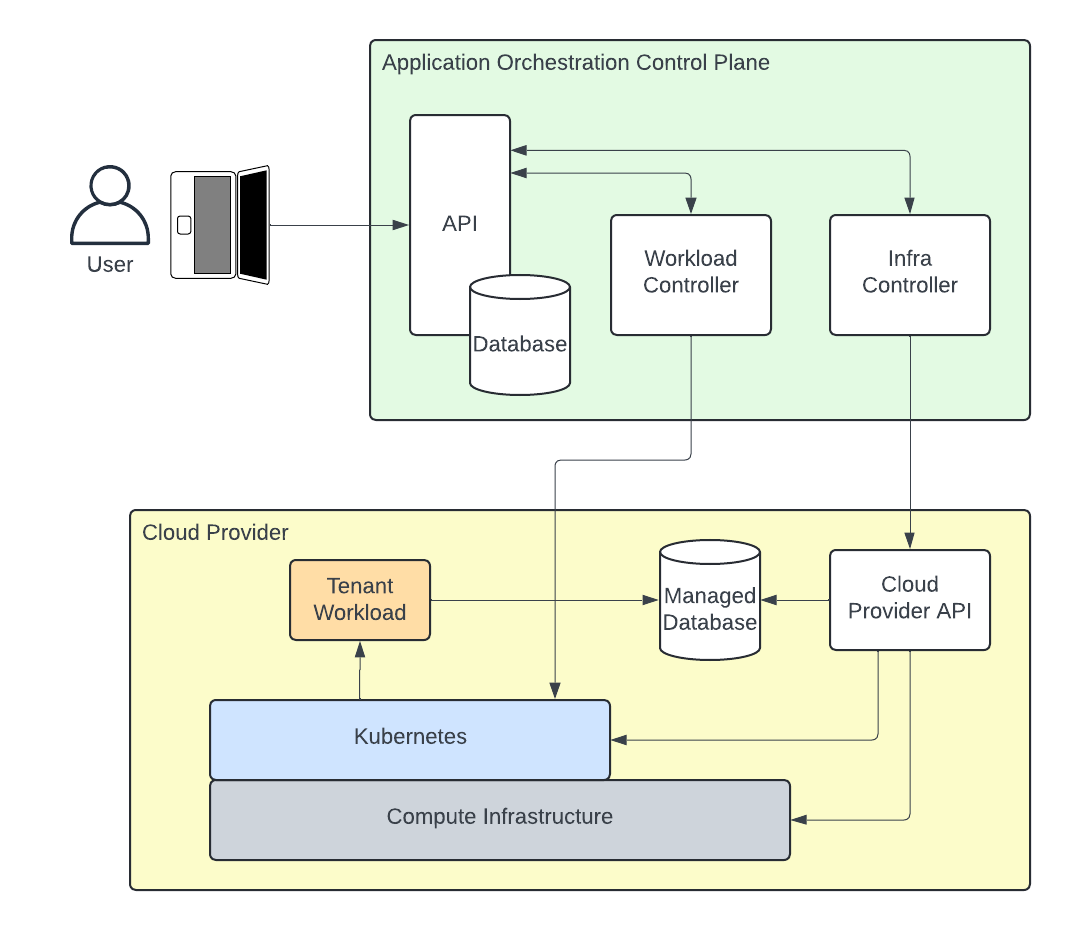
An application orchestration system like Threeport treats the workload as the primitive data type in the system and allows you to declare all the dependencies for that application. It then configures all the dependencies at run time. It stands up and configures infrastructure as needed when a deployment is requested. It deploys and configures a Kubernetes cluster if one doesn't already exist that meets the app's requirements. It installs any support services not currently available and sets them up for your app. It provisions the cloud-provider managed services needed by your app, making it accessible on the network and configuring both ends of the connection so your app can access it.
An application orchestration system also shepherds the continuous delivery of your software in an API-driven, declarative fashion. When you build new containers for your app, it will be updated in the manner that you wish without further intervention if that's what you desire.
Until now, the application dependencies listed above have typically been managed in different workflows. Infrastructure provisioning, Kubernetes cluster deployment, support service installation, managed service provisioning and tenant application deployment have been executed independently with different tools. There has been limited success in consolidating some of these operations, but no unified control plane to reliably orchestrate them all at application run time through a declarative, API-driven delivery system.
That's what Threeport is.
What it Is Not
Threeport is not a continuous integration system. We encourage you to continue using Github actions or whatever works for you to run your automated tests and checks, and to build and push container images to your preferred container image registry. The only addition is a step at the end of your CI process that sends an HTTP request to the Threeport API to alert it that a new build is available.
Threeport is not Infrastructure As Code (IaC) - at least not in the commonly accepted definition. In reality, IaC would be better termed "Infra Config in Git," which is definitely not what Threeport is. However, if we define "code" as computer instructions, i.e. a Turing-complete programming language compiled to bytecode or machine code, as distinct from "config" which consists of instructions for a program that was written with "code," we begin to describe Threeport. Using these definitions, Threeport does encompass IaC. It is software that manages infra as a dependency of your application. This critical difference is you do not define in granular detail how your infra should be configured with thousands of lines of JSON or HCL. You declare what your app needs to run, and Threeport configures the infra for your app.
A Note on Abstractions
At this point, you may be wondering, "What if Threeport doesn't configure my app's dependencies exactly how I need them?" Our approach to this issue is two-fold: Threeport employs sane defaults and conventional best-practice configurations for common implementations. However, we understand that some systems require detailed customization, so we expose the underlying controls for fine tuning Kubernetes resources where necessary. Cloud provider infrastructure is a more challenging since there's no industry standard API for those (alas OpenStack). For these situations, and any other unique requirements, we are working on an SDK that allows you to readily extend the Threeport control plane with custom implementation logic. This ensures you never encounter a road block while maintaining a cohesive, unified system.
In short: make the common use cases super easy while accommodating any imaginable use case so individual users and the community at large can add the features they find useful.
How Does It Work?
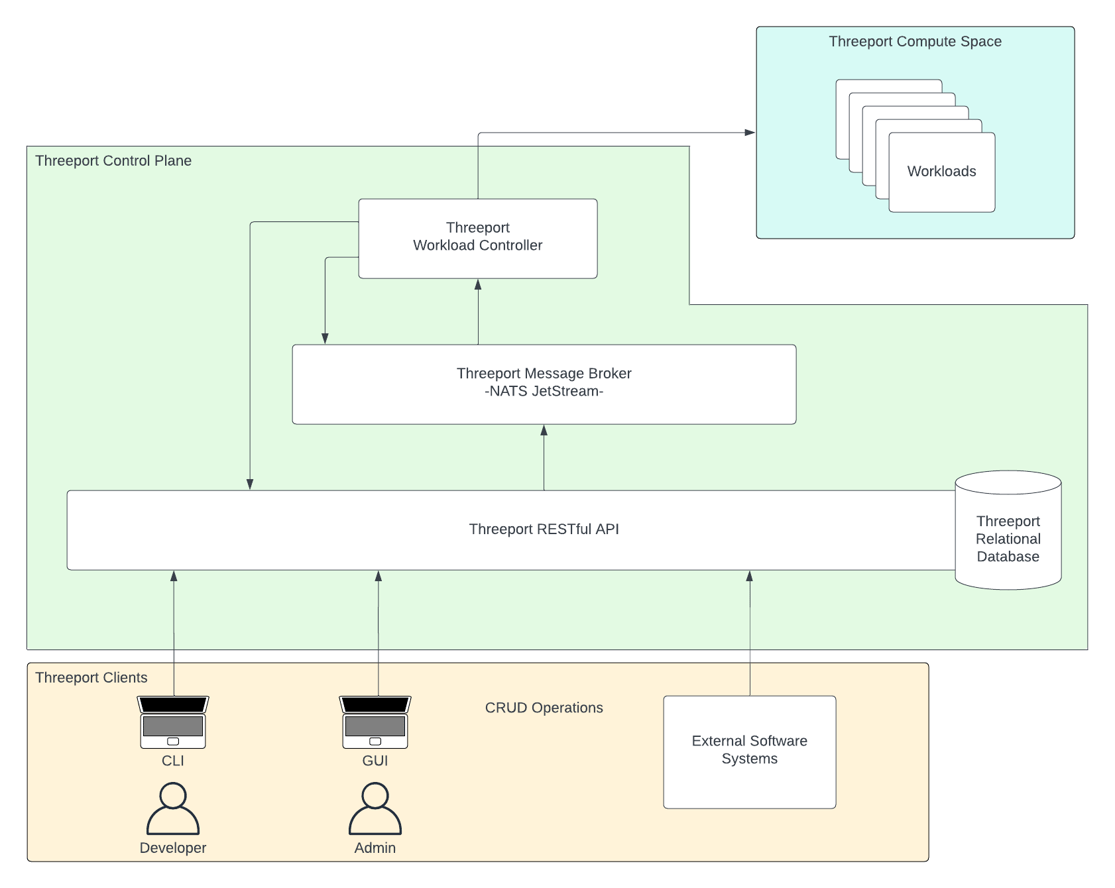
At the heart of the Threeport control plane is a RESTful API that accepts CRUD requests for objects that represent workloads and their dependencies. The API stores that data in the system's persistence layer, provided by CockroachDB. Once changes have been persisted, the API sends notifications to controllers via the NATS JetStream message broker. The controllers are responsible for reconciling the state of the system in response to changes. If a change necessitates infrastructure, the controller calls the cloud provider API to provision or remove the infra. If a change is required to Kubernetes resources, the controller calls the relevant Kubernetes API and makes the required updates there.
We provide a CLI called tptctl to manage Threeport and workloads on it. You can use it to install new instances of the Threeport control plane as well as deploy workloads.
If you'd like to try out Threeport, or if you'd like to learn more about its architecture, visit our user docs. If you'd like to receive updates as we release new versions of Threeport, sign up here. And if you have questions or feedback, hit us up in Discord.