By Richard Lander, CTO | April 12, 2024
Application Orchestration is a new approach to software delivery in which software controllers orchestrate the delivery of applications and their dependencies into a runtime environment.
The context for this blog post is cloud-native software, i.e. containerized applications running on Kubernetes. App orchestration isn't constrained to these technologies, however it is most beneficial there so we'll be talking about the topic in that context.
Before we get into the details, it's helpful to start with common practice as it exists today.
State of the Art Today
Pipeline-based delivery systems (Continuous Delivery and GitOps) are commonplace today. They generally manage a chain of CLI programs that humans use to configure software systems and deliver them into their runtime environment.
This approach is useful in that practitioners start in testing and development with CLI tools like Helm and Kustomize. They iron out their Helm charts and Kustomize configs in early stages and these CLI tools also lend themselves well to shell scripting to improve velocity and repeatability while iterating. Then these charts and configs can be migrated over to GitOps systems like Argo CD for automated releases.
Taking Argo CD as a good example, DevOps engineers can use Argo's custom Kubernetes resources to define how the charts and configs get tied together. Everything can be stored in source control and allow git triggers to fire everything off when updates are made to those assets.
This all sounds great in theory and works fine in simple environments. However, the more complex software delivery gets, the more brittle and toil-laden this approach becomes.
Problems With Pipeline Delivery
Diminishing Returns Over Time
In simple use cases, templating and overlay tools like Helm and Kustomize are wonderful. They deliver the needed configurability in short order. This is a large reason why they've become so prevalent in software delivery to Kubernetes environments. Platform teams get a killer return on investment early in development.
However, as time passes and requirements stack up, the templates in Helm charts accumulate many variables as well as the need for conditional and looping logic. Templating languages are pretty awful for this. There is a reason why web application developers keep as much logic as possible out of the templates that render HTML. General purpose programming languages are far superior for providing variable substitution and for encoding complex logic. The same applies to overlays. You can only overlay so many values in different text files before it becomes a maze that is difficult to navigate if you haven't walked it recently.
The relationship between complexity of your software delivery concerns and maintainability of your pipeline-based delivery systems look something like this:

An App is Much More Than Its Kubernetes Resources
Many applications use managed services as a part of their application stack. Let's say your production workload uses an RDS database in AWS. Spinning up an instance of your application, including its database, is challenging using pipeline-based delivery when that delivery system is designed to primarily handle Kubernetes resources. If you're using Terraform to deploy your RDS instances, you need to capture outputs, such as the database network endpoint, and feed that into the Kubernetes configuration for your application - Helm or Kustomize. These overlapping concerns are troublesome using different tools that are not natively interoperable. You can accumulate a lot of glue to keep the system together. And if any small piece of glue comes unstuck, the whole pipeline breaks down.
The best case end result is:
- Considerable effort in applying and maintaining automation glue.
- Manual toil in granular management of config values at delivery time.
The worst case end result is pipelines that break down at critical times and require troubleshooting complex templates and configs.
Support Services
Kubernetes alone is not an application platform. It provides an excellent foundation for one but it needs many support services installed on it to provide network ingress, TLS termination, DNS management, observability, secrets management and many more. The Cloud Native Computing Foundation landscape has a dizzying number of projects to provide solutions, so your options are not limited. However, tying your applications into these support service dependencies is non-trivial, even once you've found and installed the right support service solutions. Pipeline-based delivery can install those support services, but that must happen as a prerequisite to workload delivery. That is to say, a platform team must spin up each Kubernetes cluster and install all the support services that might be needed by tenant workloads. As the capabilities of your platform grow, this leads to many support services deployed when they may not be needed. All of this is because a pipeline-based delivery is not well suited to installing support services in response to the requirement of a workload that is being delivered. They just aren't cut out for the logical processing required for this kind of system.
As a consequence, you often have to deploy a lot of support services that consume considerable compute resources but are not always used. A testing or dev cluster will take longer to spin up and have much more in it that is needed or wanted. The alternative is to provide a complex set of different environments that support different workloads, obligating the platform user (developer) to have granular knowledge of the different environment profiles.
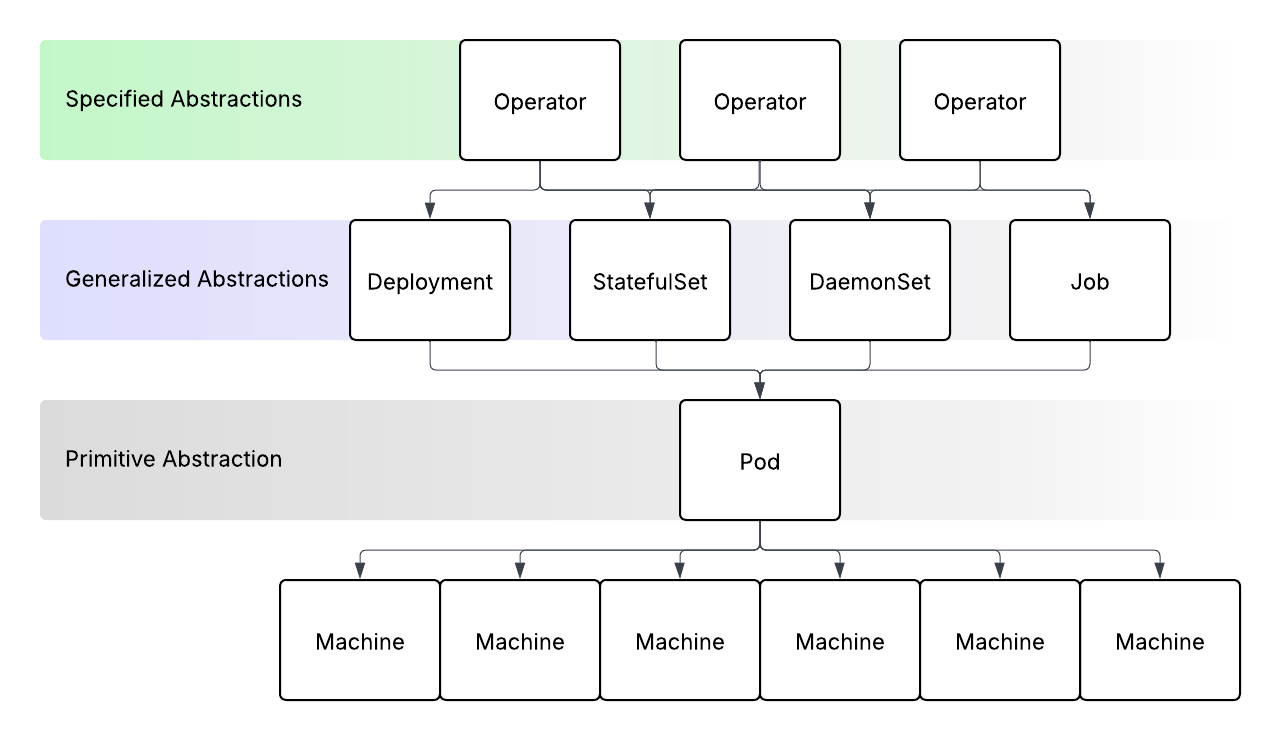
Kubernetes
Kubernetes clusters themselves are a challenge to manage in pipeline-based systems. Every organization needs multiple clusters for different tiers of operation (testing, dev, staging, production), different locations, and possibly different cloud providers. Kubernetes clusters are, themselves, dependencies for a cloud native application. Providing those on-demand when application delivery is triggered is pretty challenging. Projects like cluster-api offer a way to do this with Kubernetes custom resources, but in a pipeline-based system, the business logic you can apply to managing these clusters is limited, and you're always managing yaml manifests that require careful configuration for everything to go right.
Usually, dedicated platform teams are required to pre-provision Kubernetes clusters for use, increasing toil and decreasing the agility and productivity of engineering teams.
The fact of the matter is that cloud native applications have a lot of complex dependencies. And pipeline-based delivery is not well suited to managing complex dependencies.
Application Orchestration
Application Orchestration uses a control plane with purpose built controllers for different parts of the system rather than CLI tools that are chained together in a pipeline.

In this simplified example there are just two controllers:
- Infra Controller: responsible for calling cloud provider APIs to manage compute infrastructure and managed services there.
- Workload Controller: responsible for calling the Kubernetes API to manage containerized workloads.
Elegant management of overlapping configuration concerns between infrastructure and workload management is illustrated by these examples:
- When the Kubernetes cluster is spun up, the Kubernetes API endpoint and credentials are stored in the database by the Infra Controller. This makes it available to the Workload Controller to deploy tenant workloads.
- When the Managed Database is provisioned, the Infra Controller stores the connection details for it in the database so the Workload Controller can provide that information to the tenant workload at deploy time.
Application orchestration is distinctly different from pipeline systems in the following ways:
- An API is provided for access to state. This provides an interoperability layer that makes integrations a first-class consideration. This opens the door to several benefits:
- Integrations with CI systems that call the app orchestrator’s API once a workload’s testing and build processes are complete. No longer do git operations need to be triggered to set off delivery operations.
- Integrations with systems that operators use. CLI tools, web portals or any custom in-house system can now retrieve data from the app orchestrator through its API.
- Integrations with compliance software, security audit systems, or any kind of observability system become possible.
- State is stored in a database. The source of truth for a pipeline-based system is usually a git repo. Git is excellent for version control of software source code. It is primarily a human interface for engineers to coordinate on adding features and fixing bugs in source code. It is far less well suited to storing configuration for a system. Databases are far superior when software - as well as humans - need to read from and write to the data persistence layer. Validation can be provided for inputs to the database and queries are far more efficient. When software needs to manage a system, databases are the ideal persistence layer.
- Software controllers reconcile state in the system. When a change is made to the database through the API, controllers make changes in the system to reconcile the state. Those controllers call cloud provider APIs, Kubernetes APIs or whichever system is needed to reconcile state. Changes that involve multiple systems can happen synchronously or asynchronously as requirements dictate. Variables are stored in the database, accessed by controllers and used to configure the system. Those variables are passed through function calls and fed to other controllers via the API when overlapping concerns between components of a software system exist.
- Extensibility is baked in. Using distinct controllers for distinct concerns opens the door to layering on more and more specific functionality. Some controllers handle common operations - such as managing resources in Kubernetes. Others may have highly customized functionality for a specific application. So, instead of implementation details for an application being built into templates and configurations, they are written in the source code of a controller. The end result is an abstraction of all the underlying implementation details for the user so they are able to invoke very complex systems with a single request.
Advantages of App Orchestration
True orchestration of software delivery becomes possible with application orchestration. Overlapping concerns for configuring all of a workload's dependencies can be elegantly handled in this manner. Some of the advantages that come about are:
- State Reconciliation: Properly designed controllers can use reconciliation loops to continue to retry an operation until it completes if some blocking condition is met at first. For example, if a workload is deployed at the same time as the Kubernetes cluster, and it takes several minutes for the cluster to become available, the Workload Controller can continue to retry the workload install until the cluster is up and the Infra Controller has provided the Kubernetes API connection details.
- Dependency Mapping: Because the app orchestration controllers are programmed to understand dependency maps, there is no limit to the number of dependencies that can be elegantly orchestrated, offloading each distinct concern to the appropriate controller to reconcile state and store relevant details in the database. This is most valuable in distributed systems that have many complex integration points.
- Extensibility: Custom functionality for specific workloads can be provided by platform engineering. They can leverage all the primitive objects and common functionality in the system and provide self-service abstractions to the users of the platform for even the most complex software systems.
Application orchestration is, in part, a framework for platform engineers to provide the most efficient software delivery operations to their developers and operations teams.
Challenges with App Orchestration
Software Development
As mentioned earlier, the CLI tools used in pipeline-based systems make it very easy to execute early stage POCs and MVPs. This is very helpful in getting software delivery systems up and running quickly.
Application orchestration offers a comparable time-to-launch for simple use cases that can leverage the existing primitive objects in an app orchestration system. However, the custom abstractions for delivering the software you built will often require building controllers instead of wrangling configs and templates. This requires a bit more up-front engineering. Good software development kits and frameworks can mitigate this, however you're always dealing with compiled, containerized, released software controllers rather than a simple git push for a config to add functionality.
The trade-off boils down to time-to-launch vs returns over time:
- Pipelines generally provide a fast time-to-launch with diminishing returns over time.
- App orchestration requires additional up-front engineering in software development with increasing returns over time. As the SDK tooling and developer familiarity improves, the time-to-launch cost will come down to be comparable with pipeline systems.
App Orchestration Control Plane
The pipeline-based approach has a wealth of options that are relatively straight forward to install and use. Again, this helps in getting up and running quickly.
App orchestration requires a control plane that is, in and of itself, a complex distributed software system. Good installation and bootstrapping mechanisms mitigate this. So can managed service providers that offer hosted app orchestration control planes. But it is, nonetheless, a challenge to navigate.
What This Means for Developers
The holy grail of a self service experience for developers becomes available to all teams, large and small, with app orchestration. Simple use cases can be managed with primitive objects and general-purpose controllers. Complex systems will require extension and customization, but the end result will pay dividends and provide increasing returns over time.
What This Means for Platform Teams
App orchestration offers platform engineers the opportunity to provide significantly outsized value from what they've been able to deliver in the past. It dovetails exceptionally well with the Kubernetes operator pattern and allows community collaboration around commonly encountered use cases and challenges. It means they don't have to re-invent the wheel each time they develop a new cloud-native application platform or extend an existing one.
App orchestration offers an opportunity for an industry standard that makes platform engineering more effective by orders of magnitude.
What This Means for Software Delivery
In a word: Efficiency. As modern cloud native software becomes ever more feature rich, complex and distributed, efficiency in software delivery will become more critical. Greater efficiency leads to lower costs and better software as the net results.
Threeport
Threeport is an open source application orchestrator. It was developed by platform engineers with a wealth of experience and a recognition that a better system for software delivery is possible. The Threeport CLI is available to download on GitHub. You can install a Threeport control plane locally or in AWS and try it out for yourself.
Qleet
Qleet provides fully managed Threeport control planes. The engineers at Qleet developed Threeport and are available to support you every step of the way in leveraging application orchestration for your company's software delivery.

