Nothing New Under the Sun
By Randy Johnson, Staff Software Engineer | Nov 8, 2023
Earlier this week we announced Threeport, an open-source application orchestrator. While this may sound like a radical departure from what you’re used to, we wanted to take the time to discuss why we think it is a logical next-step in the evolution of software. We will take a look at a brief history of computing and show that Threeport fits nicely into it as a solution to common problems that development teams face today.
The Evolution of Software Delivery
Software is all about abstractions. Within each layer of a typical software engineering stack we tend to follow a similar pattern: solve problems with the simplest solution possible (often homegrown tooling and scripts), until that approach breaks or no longer scales. Then, we’ll either create a new abstraction or use a well-established one that’s been proven elsewhere.
At the infrastructure layer, this has taken many forms. Physical infrastructure has been abstracted by VMs. Within these VMs, we developed containers to handle the problem of process isolation. To solve the problems of scheduling, bin-packing, service discovery, and networking for all of these containers, we ended up with container orchestration tools like Kubernetes. All of these paradigm shifts have a number of things in common:
- Adherence to Unix-like philosophy - They all make modular, composable solutions to solve their respective problems.
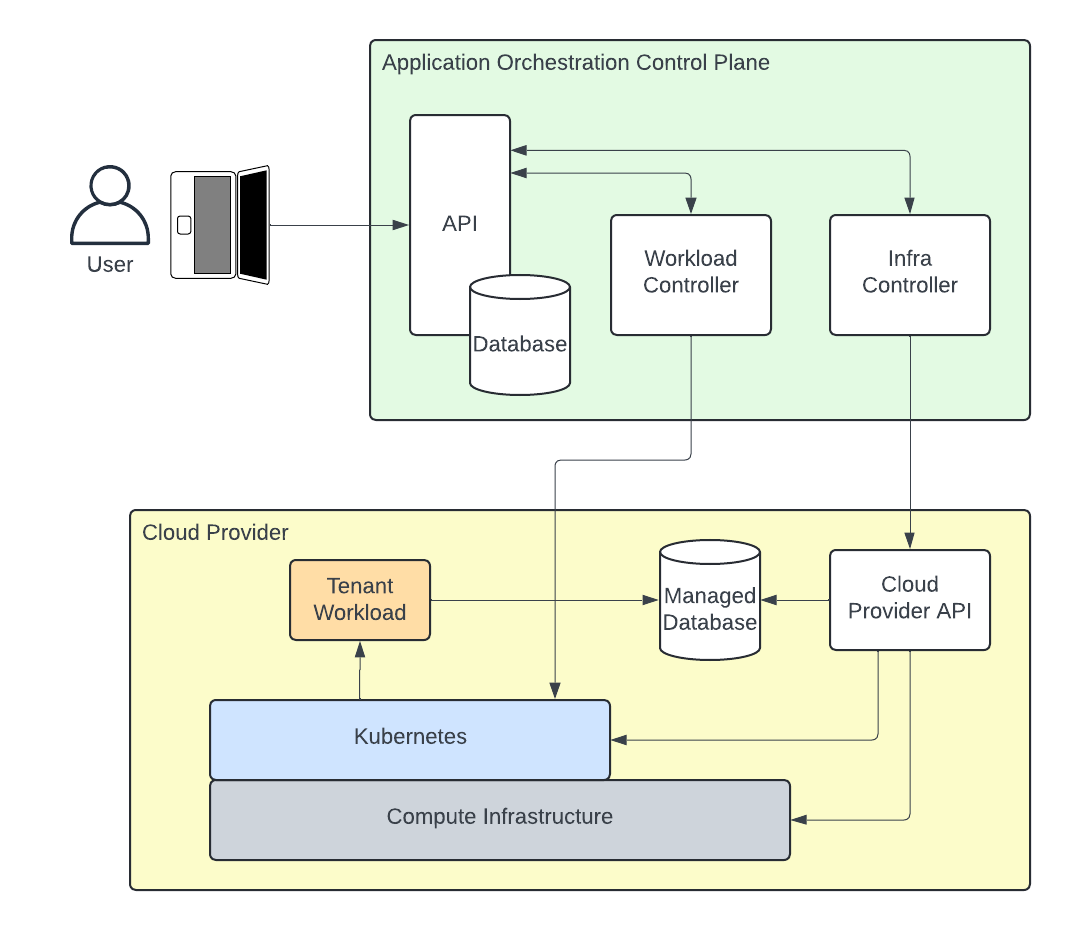
- Actively managed - They introduce some software component that actively manages concerns for a user in a level-triggered fashion. VMs have hypervisors, Docker Containers have the Docker Daemon, and Kubernetes has the control plane.
- Programmable interface - They each present a convenient programming interface for the next generation of tooling to build on top of. When the latest abstraction layer becomes somewhat stable and the industry comes to a consensus on it, we start seeing projects pop up to solve problems at the next layer.
While each new abstraction presents a programmable interface for concerns that are in-scope, there is also a distinct set of problems that remain out-of-scope. The easiest way of tackling these leftover concerns is often called “automation” and involves various CLI tooling packaged into a script containing some form of synchronous, event-triggered pipeline. For example, configuring a bare-metal server to host an application was eventually replaced by simply asking a hypervisor to set up a new VM for us. In either case, the client making the request was a problem left for a pipeline. The thing that evolved over time is where the complexity of this action is handled. If you’re familiar with the concept of shift-left testing (designing development processes to catch errors as early as possible), this can be thought of as the opposite for handling complexity: while we use simpler CLI tools in our workflow, we “shift right” the underlying complexity and delegate it to software.
What This Looks Like Today
Nowadays, things aren’t a whole lot different. An advanced infrastructure may consist of a Kubernetes cluster whose configurations are generated via various YAML-wrangling tools in a pipeline before being deployed. It’s a similar story for provisioning this cluster and its underlying infrastructure via infrastructure-as-code tooling. On one hand, this is a big improvement over what this might have looked like without a hypervisor, Docker daemon, or Kubernetes control plane. On the other hand, we’re still left with pipeline tasks which can often be categorized as undifferentiated heavy-lifting. In this 2006 AWS blog post on this topic, Jeff Bar writes:
Remarkable aspects of this heavy lifting include server hosting, bandwidth management, contract negotiation, scaling and managing physical growth, dealing with the accumulated complexity of heterogeneous hardware, and coordinating the large teams needed to take care of each of these areas.
Many of these problems have thankfully “shifted right” since then and are now reduced to APIs. However, the overall pattern remains. At Qleet, we believe we’re due for an appropriate abstraction to handle the undifferentiated heavy-lifting of today.
What’s Next?
At each stage we discussed previously, operations teams were left with a set of common problems. They had to re-invent the wheel until the next feasible abstraction came along to make their lives easier. Let’s go over today’s problems we believe are ready to be abstracted.
Before we dive in, it’s helpful to revisit why we’re here in the first place. All of the previously discussed technologies are a small part of one big problem - “I have an application that serves a core business function and it needs to live somewhere.” The technologies themselves are not an outcome that we care about, but meeting customer needs is. This is a useful starting point for discussing the motivations behind Threeport.
Let’s say Acme Corp. has a web application that is ready for production. What’s the highest-level, most generic description of what this application really needs?
- Networking - A domain, and the plumbing between it and the web application.
- Uptime - The application must always be available, regardless of the load being placed on it.
- Efficiency - We need to meet the above requirements in a cost effective manner.
- Updates - We need the latest version of our web application deployed to deliver the most value to customers.
- Dependencies - Other services the web application depends on must be available, and meet all of the above requirements. In this example, let’s use a database.
With the current state of DevOps and Platform Engineering, there are dozens of ways to accomplish the above using chains of disparate tools. At the end of the day, all DevOps and Platform Engineering teams are solving for the same set of requirements separately and in parallel of each other. Our hypothesis with Threeport is that this set of problems represents what should be abstracted in the next evolution of software delivery. Similar to advancements before with VMs, containers, and container orchestration, what if we could “shift-right” the redundant complexities before us into an abstraction that is actively managed for us by software? In this regard, Threeport is just the next iteration of Unix philosophy and software engineering applied to a set of software delivery problems - there’s nothing new under the sun.
Ready to get started with Threeport? Check out our getting started guide here.